
在文章《如何识别和定位架构问题》中,我描述了如何识别架构中已经存在的问题。文章重点关注在组件的边界以及组件之间的关系上,这部分在架构中非常重要,一旦有问题,都会是比较严重的问题。
除此之外,是不是还有其他的问题依然需要优化呢?答案是肯定的,架构优化的目标是为了提升系统的可用性和可扩展性,减少线上问题,进而提升用户体验。因此,只要是能够帮助达成这个目标,都可以纳入架构优化中。在这篇文章中,我们就展开讨论架构优化的几个方向。
从技术层面来说,架构优化要解决的就是系统中的不良设计,宽泛来说都可以归结为技术债。在《技术债的前世今生》中我从技术债产生原因的角度讨论了技术债分类,但并没有针对技术债的内容进行分类,在2014年Nicolli S.R. Alves等发表的论文《Towards an Ontology of Technical Debt》中,定义了13种技术债类型:
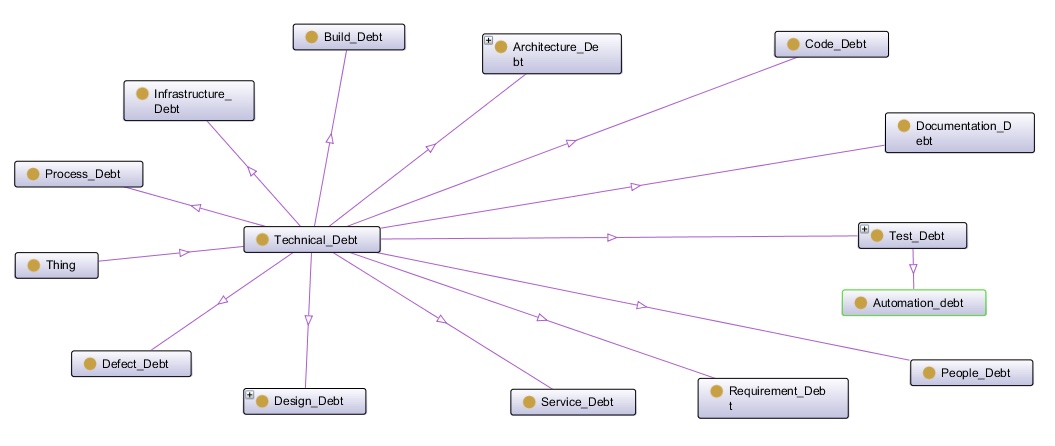 图片来源:论文《Towards an Ontology of Terms on Technical Debt》中 Fig. 2
图片来源:论文《Towards an Ontology of Terms on Technical Debt》中 Fig. 2
Dwarak Govind Parthiban在论文《Examination of tools for managing different dimensions of Technical Debt》 中将技术债维度定义为:
 图片来源:论文《Examination of tools for managing different dimensions of Technical Debt》中 TABLE IV
图片来源:论文《Examination of tools for managing different dimensions of Technical Debt》中 TABLE IV
本文中主要关注技术设计和实现层面需要优化的内容,不考虑组织、人员以及流程等方面的问题,也暂时不讨论测试、已知Defect以及文档相关的债务,虽然这些债务也很重要。结合以上两篇论文,从架构的不同维度,我们可以将架构优化的重点放在以下四个方向:代码实现(Code Debt)、组件设计(Design Debt)、架构设计(Architecture debt)和基础设施(Infrastructure Debt)。
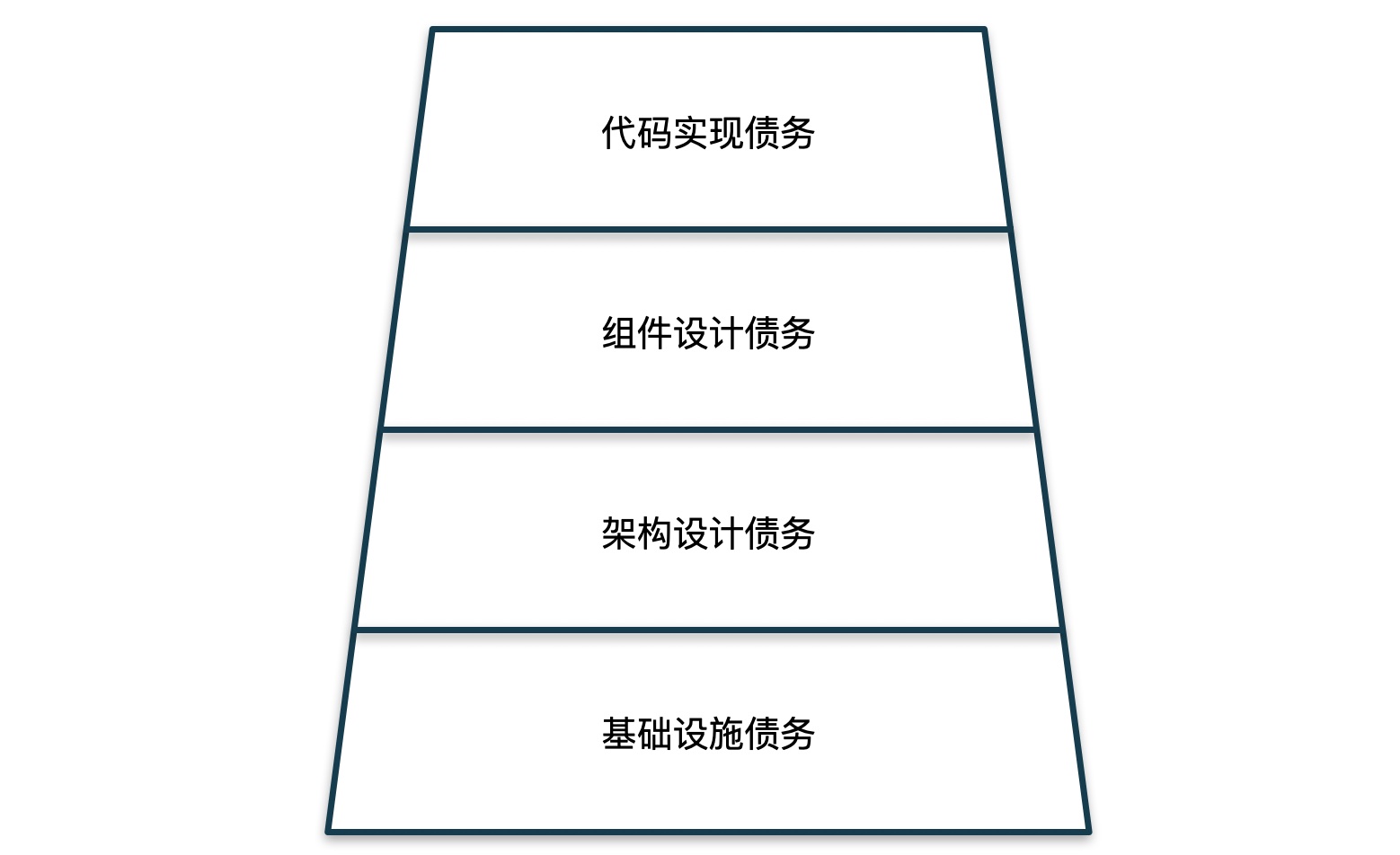
代码实现(Code Debt)
代码实现债务指在开发过程中,没有遵守相关的规范产生的问题,这些问题会对代码的可读性和可测试性产生很大影响。另外很多细节的设计不合理也会带来非常严重的稳定性问题,举两个例子:
- 大量无效的日志输出,占用磁盘资源,极端情况下会出现因磁盘容量不足导致线上故障
- 循环中进行数据库或集成接口的调用,这种接口的性能在请求数据量较大时影响非常严重,对数据库和集成的服务产生非常大的压力,进而影响系统的稳定性
通常,代码的问题可以通过源代码扫描工具来识别,比如PMD、ESLint、CheckStyle、Sonaqube等。但类似日志或循环中进行数据库读写这种问题很难通过自动化工具识别,针对这些场景,可以通过CodeReview,定期的日志分析,Tracing数据的分析等方式来识别。
组件设计(Design Debt)
这里的组件设计指的是架构中一个组件(比如一个微服务)的内部设计,组件内部的设计可以有很多种(比如分层架构、六边形架构等),但不管如何划分一个组件内部的模块,在实际开发过程中,想做到完全符合设计预期都是很难甚至无法完成的事情。因此,一定会产生很多因设计不合理导致的技术债,比如:
- 封装不足,每个服务都有类似的功能,但有各自的实现,不完全统一
- 过度封装,比如使用common包这样的公共依赖,希望用大而全的共享库解决问题,然而实践中会产生各种版本冲突问题,参见《消灭微服务的坏味道 之 共享库》
- 违反SOLID原则的设计,超大API或者超大的类
架构设计(Architecture debt)
架构设计债务主要指在软件整体架构上存在的问题,典型的如微服务边界划分不合理,职责不清。
然而,这种问题很难快速识别,也很难通过简单的代码修改来偿还。这通常需要对业务和架构有深刻的理解,并辅助以一些工具和实践方法(如DDD或8X Flow等建模分析方法)。可以参考《如何识别和定位架构问题》文中对架构组件边界和集成方式的分析方法。
架构设计债务产出的方案重点关注在因职责不清,交互方式不合理导致的问题,可能有以下几种(以微服务架构为例):
- 微服务的拆分或合并
- 微服务间集成方式的优化(同步调用或异步事件)
- 第三方集成策略的优化(识别业务主体,根据交互实时性要求调整集成策略)
基础设施(Infrastructure Debt)
软件系统的基础设施可以分为两大类:
- 软件运行的环境以及相关的基础设施依赖,如VM、数据库、缓存等
- 软件开发过程中依赖的一些基础框架
- 技术框架的选型,如Java、React、Spark等
- 依赖的开源软件,如log4j等
- 自封装的基础设施包,比如日志处理、数据源管理、秘钥管理等
基础设施承载了整个软件的运行环境,一旦有问题,也是影响最严重的,比如VM出了问题,所有部署在这个VM上的服务都会受到影响,再比如框架代码一旦发现漏洞,影响的也将是所有的服务。
以上四个方向,从上到下范围逐渐变大,产生的影响也逐渐变大,因此通常情况下,在识别到问题后,处理优先级应该是反过来,先从基础设施开始,最后是代码实现。然而,真正操作过程中,还要根据问题的严重程度以及开发的投入产出比作为额外的信息,来辅助优先级排序。